~3 min read
Anatomy of a Self-Service Analytics AI Agent
How we built a multi-agent system that turns natural language questions into Databricks SQL and Power BI DAX: what works, what doesn't, and what's next.
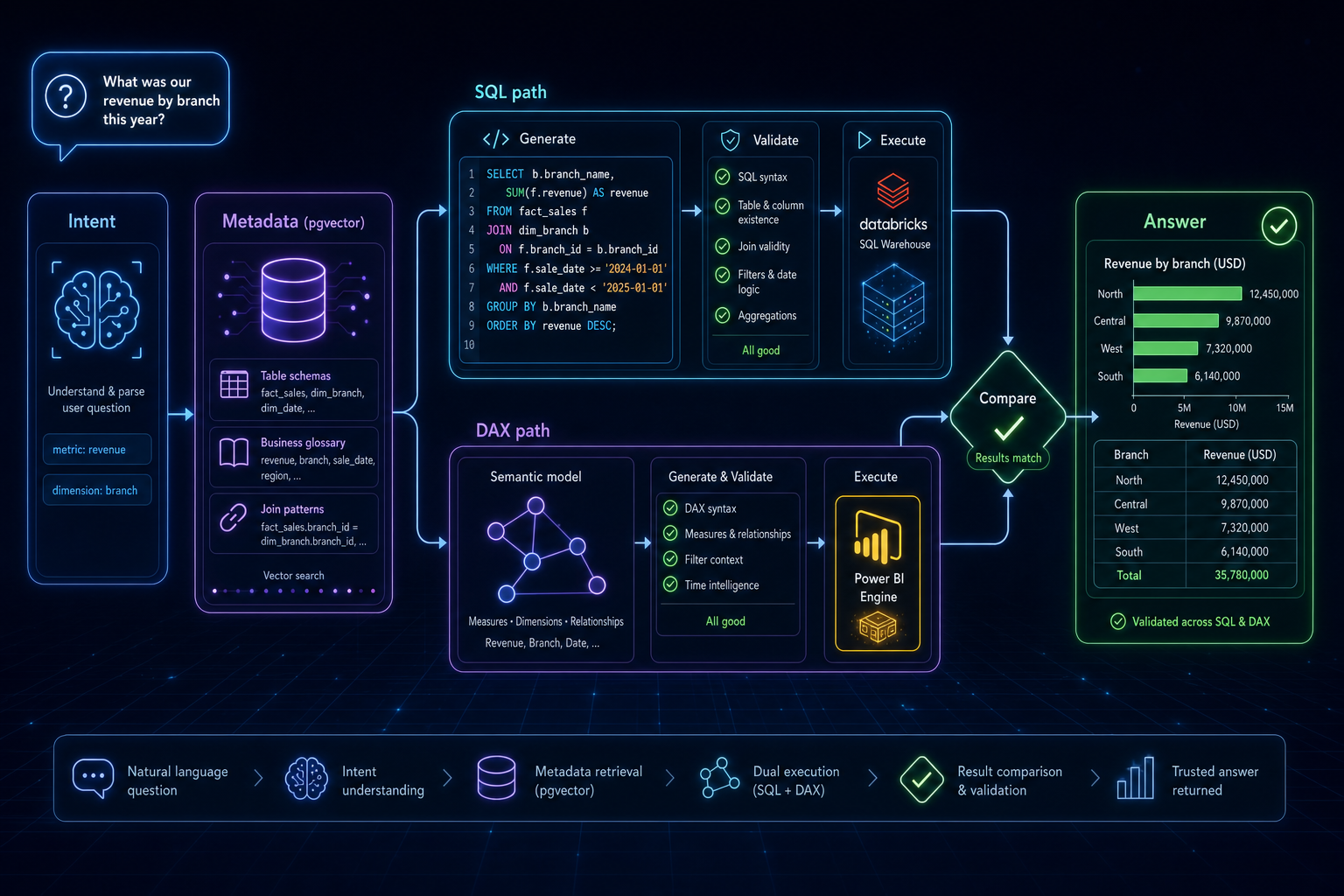
Business users ask questions like “What was our revenue by branch this year?” and expect an answer, not a ticket in the BI backlog. We built an AI agent that answers those questions by generating and executing real queries against our data platform. This post walks through the architecture, what we got right, and what we’d do differently.
The big picture
The system is a FastAPI application orchestrating 16 specialized LLM agents (LangChain/LangGraph on AWS Bedrock) in a layered architecture:
HTTP Layer FastAPI routers + SSE streaming
Application AgentService, ConversationService (orchestration)
Domain 16 specialized agents (intent, metadata, SQL, DAX, ...)
Infrastructure Bedrock, Databricks SQL Warehouse, pgvector, Power BI RESTA question flows through a pipeline of small, single-purpose agents:
- Intent parser — classifies the question (analytics query? definition lookup? greeting?) and extracts structured intent: metrics, dimensions, time range, query type.
- Metadata agent — retrieves relevant context from a pgvector store: table schemas, join patterns, glossary terms, and curated example queries.
- SQL generator → validator → self-corrector — generates Databricks SQL, statically validates it (schema allowlists, join-pattern checks, column existence), and auto-repairs failures.
- Query executor — runs validated SQL against the Databricks SQL Warehouse.
- Power BI path (parallel) — discovery → DAX generation → DAX execution against Power BI semantic models.
- Result comparator — picks the better answer between the SQL and DAX paths.
- Visualization + summary agents — produce a chart config and a plain-language answer.
When intent is ambiguous, a clarification agent short-circuits the pipeline and asks the user a follow-up question instead of guessing.
Metadata as code
The most important design decision in the whole system has nothing to do with agents: all domain knowledge lives in versioned YAML files, loaded into pgvector:
- Table schemas — columns, types, descriptions, PII tags
- Join patterns — exact join conditions the generator must use verbatim (“USE EXACTLY — DO NOT MODIFY COLUMN NAMES”)
- Glossary — business definitions with authoritative calculations
(e.g. revenue =
SUM(semantic.profitability.revenue)) - Example queries — curated question→SQL pairs the generator can adapt
This makes the agent’s knowledge reviewable in pull requests, diffable across releases, and testable, which leads to the second key decision.
Evaluation as a first-class citizen
Every change to prompts, metadata, or the data model runs through an MLflow-tracked evaluation pipeline: ~44 YAML test cases scored on a weighted composite:
| Metric | Weight |
|---|---|
| execution_success | 0.40 |
| sql_accuracy | 0.30 |
| metadata_relevance | 0.20 |
| intent_accuracy | 0.10 |
Test cases support dual-schema expectations (OR-groups of acceptable table sets), so
the same suite scores the agent before and after a warehouse remodel. When we migrated
from core.* to semantic.* tables, this harness is what told us exactly which 25 of 42
cases regressed and why (the agent kept emitting deprecated column names).
What works well
- Small agents, explicit contracts. Each agent does one thing and passes typed state (Pydantic models) forward. Debugging means inspecting one hop, not one giant prompt.
- Generate → validate → self-correct. Static validation (forbidden DDL/DML, schema
allowlists,
alias.columnexistence checks against metadata) catches most LLM hallucinations before anything touches the warehouse. - Dual-engine redundancy. Running SQL and DAX in parallel and comparing results hedges against weaknesses in either path.
- Curated examples beat clever prompts. The single highest-leverage quality lever is adding a good example query for a question pattern, with no code change required.
- Honest failure modes. An error catalog maps internal exceptions to user-facing messages; stack traces never leak through the API.
Where it hurts
- In-memory conversation state.
ConversationServicekeeps history in process memory. A pod restart loses context; horizontal scaling needs sticky sessions. This is the most obvious production liability. - Retrieval is schema-version blind. Old (
core.*) and new (semantic.*) metadata coexist in the vector store with no deprecation marking. Ranking is vector similarity plus token-overlap bonuses, so a stale example query can outrank the correct one and teach the generator deprecated column names. We patched this with ranking boosts and penalties, but it’s a band-aid, not versioning. - Validation is post-hoc and advisory. Column checks run after generation and mostly emit warnings. The LLM is never hard-constrained to the retrieved schema.
- SSE with a 50-second timeout. Long queries fall back to background execution and
client polling of a
/statusendpoint. Workable, but it means two code paths for one flow. - Hardcoded knowledge leaks into prompts. The SQL generator’s system prompt embeds example snippets with real column names. When the warehouse changed, the prompt silently kept teaching the old schema.
What we’d improve next
- Externalize conversation state to Postgres or Redis — table stakes for multi-replica deployment.
- Metadata lifecycle management: version and deprecation fields in every YAML doc, hard-filtered at retrieval time instead of soft ranking penalties. Loading should fail if a join pattern references a column that doesn’t exist in any table schema.
- Schema-constrained generation: validate the plan (tables + joins) against
metadata before SQL is written, and add a Databricks
EXPLAINdry-run gate so binder errors never reach the user. - Keep prompts schema-free. Everything table- or column-specific belongs in retrievable metadata; system prompts should teach dialect rules and patterns only.
- Close the loop with production telemetry: mine the query observability logs for uncovered question patterns and auto-propose new test cases and example queries.
Takeaway
No single agent is the strength of this architecture. The strength is the feedback loop: metadata as reviewable code, an evaluation harness that scores every change, and production logs feeding new test cases. LLMs are the least stable component in the stack; everything around them is built so that when they drift, we know the same day, with a number attached.